df, df_attributes = get_sample_data()core
A few core functionalities to work with data representing bill of materials
get_sample_data
def get_sample_data(
):
Return sample BOM data (df) and item attributes (df_attributes) for demonstration purposes.
At this point, we have:
df– Bill of Materials table (predecessor, successor, quantity)df_attributes– Item attributes table (component_type, cost, etc.)
Core Functions
We create one large directed graph containing all nodes and edges from df. For node attributes, we can optionally merge data from df_attributes.
build_complete_graph
def build_complete_graph(
df, df_attributes:NoneType=None
):
Build a directed graph (DiGraph) from the BOM DataFrame. Optionally enrich nodes with attributes from df_attributes.
G = build_complete_graph(df, df_attributes)
print("Number of nodes:", G.number_of_nodes())
print("Number of edges:", G.number_of_edges())Number of nodes: 20
Number of edges: 21If we want to see which assemblies or products contain a given part, we can move upwards in the graph (following edges backwards).
get_all_predecessors
def get_all_predecessors(
G, node_id
):
Return a list of all predecessors (ancestors) of node_id. This effectively finds all assemblies or parent items that contain node_id.
Now, we can answer questions like: > Where is component ‘MOTOR_A1’ installed?
get_all_predecessors(G, 'MOTOR_A1')['PUMP_RV1', 'PUMP_RV2', 'PUMP_CL1']Similarly, we can move down the graph to find all sub-components or child items of a given product or assembly.
get_all_successors
def get_all_successors(
G, node_id
):
Return a list of all successors (descendants) of node_id. This effectively finds the complete set of parts that make up node_id.
Now, we can answer questions like: > What component are installed in ‘PUMP_RV1’?
get_all_successors(G, 'PUMP_RV1')['MOTOR_A1', 'CASE_STD1', 'VANE_ASM1', 'OIL_SYSTEM1', 'VANE_001', 'BEARING_01']We can select a sub_graph by giving a root node and then searching for all successors.
select_subg_by_root
def select_subg_by_root(
G, root_id
):
sub_g = select_subg_by_root(G, 'PUMP_RV1')
sub_g.nodes()NodeView(('PUMP_RV1', 'VANE_ASM1', 'MOTOR_A1', 'BEARING_01', 'OIL_SYSTEM1', 'CASE_STD1', 'VANE_001'))For a multipartite (hierarchical) layout in NetworkX, each node must have a level attribute. The “level” is typically “0” for a root product, “1” for its direct children, “2” for those children’s children, etc. This function automatically detects the root(s) (any node with no incoming edges) and assigns levels by breadth-first search.
get_all_roots
def get_all_roots(
G
):
Returns a list of nodes with no ingoing edges (root_nodes)
add_levels
def add_levels(
G
):
Calculate levels starting from root
sub_g = add_levels(sub_g)
[(n[0],n[1]['level']) for n in sub_g.nodes(data=True)][('PUMP_RV1', 0),
('VANE_ASM1', 1),
('MOTOR_A1', 1),
('BEARING_01', 2),
('OIL_SYSTEM1', 1),
('CASE_STD1', 1),
('VANE_001', 2)]The depth of the bill of materials can give us information about the depth of added value per product.
max([n[1]['level'] for n in sub_g.nodes(data=True)])2Visualizing
Finally, we create a plotting function that can handle:
- Either a multipartite layout (if levels are assigned)
- Or a kamada_kawai layout (force-directed)
We also display edge attributes (quantity), and we allow parameter overrides (font size, node size, color, etc.) for quick styling changes.
plot_graph
def plot_graph(
G, # NetworkX graph
layout:str='multipartite', # 'multipartite' or 'kamada_kawai'
figsize:tuple=(24, 12), font_size:int=8, node_size:int=1000, node_color:str='lightblue',
direction:str='top_to_bottom', # if layout is multipartite the direction is top to bottom, to rotate set to None
label_rotation:int=45, # Rotation angle for node labels (in degrees)
):
Plot a graph with specified layout and styling.
plot_graph(sub_g)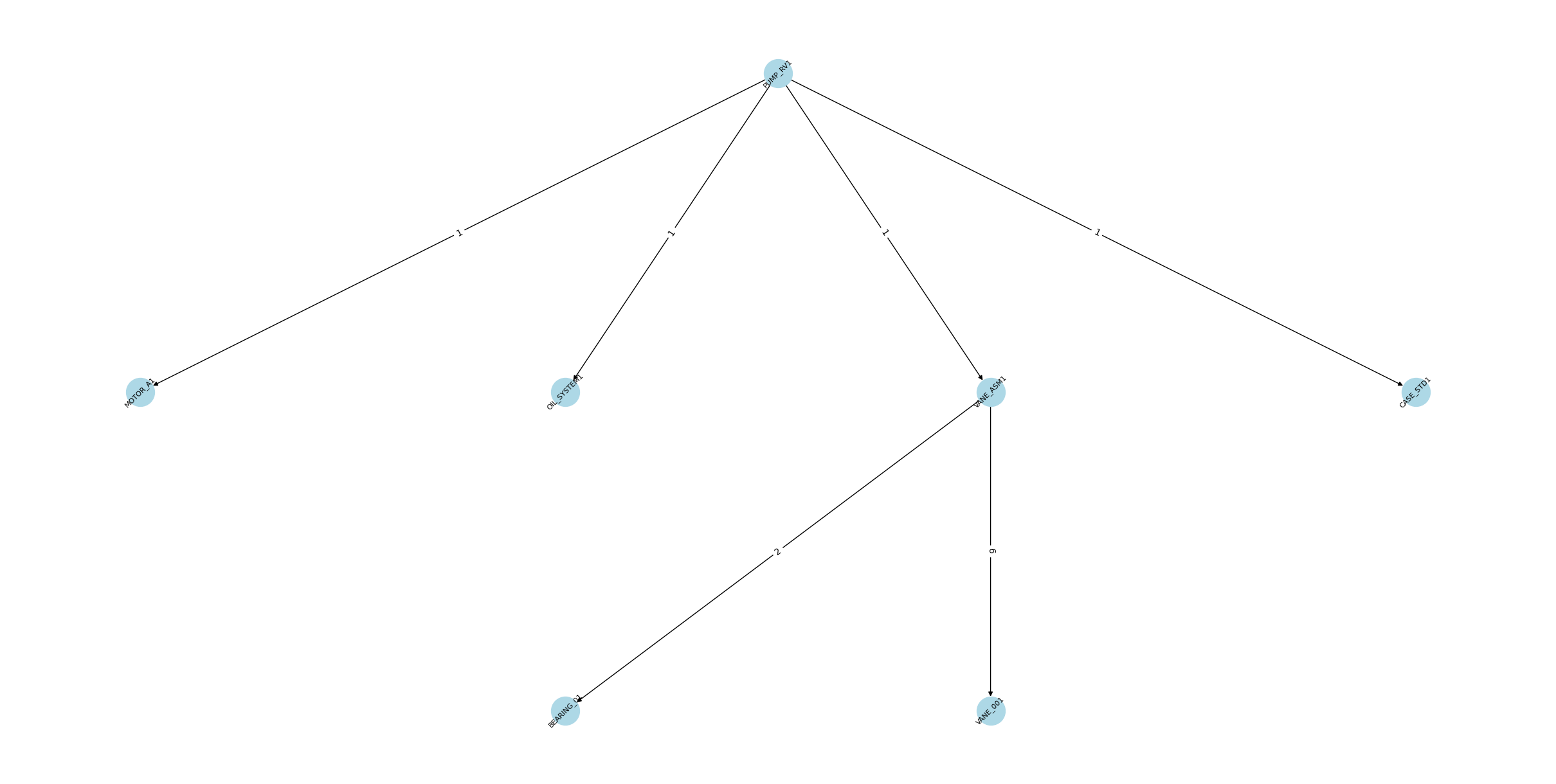
Creating a binary matrix
We can also create a binary matrix, with endproducts in the index and parts as columns. This is very helpful, for further analysis, like similarity searches and product clustering.
data = [
{"Name": "Alice", "Age": 25},
{"Name": "Bob", "Age": 30},
{"Name": "Charlie", "Age": 35}
]pd.DataFrame(data, index=['one','two','three'])| Name | Age | |
|---|---|---|
| one | Alice | 25 |
| two | Bob | 30 |
| three | Charlie | 35 |
import numpy as nproot_nodes = get_all_roots(G)
pd.DataFrame([{col:1 for col in get_all_successors(G, root)} for root in root_nodes], index=root_nodes, dtype=pd.SparseDtype("int", fill_value=np.nan))| MOTOR_A1 | CASE_STD1 | VANE_ASM1 | OIL_SYSTEM1 | VANE_001 | BEARING_01 | VANE_ASM2 | VANE_002 | MOTOR_B1 | CASE_SC1 | SCREW_ASM1 | SCREW_001 | BEARING_02 | CASE_CL1 | CLAW_ASM1 | CLAW_001 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PUMP_RV1 | 1 | 1 | 1 | 1 | 1 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| PUMP_RV2 | 1 | 1 | NaN | NaN | NaN | 1 | 1 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| PUMP_SC1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1 | 1 | 1 | 1 | 1 | NaN | NaN | NaN |
| PUMP_CL1 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1 | 1 | 1 | 1 |
[pd.DataFrame({root: get_all_successors(G, root)}).stack() for root in root_nodes][0 PUMP_RV1 MOTOR_A1
1 PUMP_RV1 CASE_STD1
2 PUMP_RV1 VANE_ASM1
3 PUMP_RV1 OIL_SYSTEM1
4 PUMP_RV1 VANE_001
5 PUMP_RV1 BEARING_01
dtype: object,
0 PUMP_RV2 MOTOR_A1
1 PUMP_RV2 CASE_STD1
2 PUMP_RV2 VANE_ASM2
3 PUMP_RV2 VANE_002
4 PUMP_RV2 BEARING_01
dtype: object,
0 PUMP_SC1 MOTOR_B1
1 PUMP_SC1 CASE_SC1
2 PUMP_SC1 SCREW_ASM1
3 PUMP_SC1 SCREW_001
4 PUMP_SC1 BEARING_02
dtype: object,
0 PUMP_CL1 MOTOR_A1
1 PUMP_CL1 CASE_CL1
2 PUMP_CL1 CLAW_ASM1
3 PUMP_CL1 CLAW_001
4 PUMP_CL1 BEARING_02
dtype: object]create_binary_matrix
def create_binary_matrix(
G, root_nodes:NoneType=None
):
Creates a binary matrix with endproducts as indices and parts as columns
b_matrix = create_binary_matrix(G)
b_matrix| parts | BEARING_01 | BEARING_02 | CASE_CL1 | CASE_SC1 | CASE_STD1 | CLAW_001 | CLAW_ASM1 | MOTOR_A1 | MOTOR_B1 | OIL_SYSTEM1 | SCREW_001 | SCREW_ASM1 | VANE_001 | VANE_002 | VANE_ASM1 | VANE_ASM2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| head | ||||||||||||||||
| PUMP_CL1 | False | True | True | False | False | True | True | True | False | False | False | False | False | False | False | False |
| PUMP_RV1 | True | False | False | False | True | False | False | True | False | True | False | False | True | False | True | False |
| PUMP_RV2 | True | False | False | False | True | False | False | True | False | False | False | False | False | True | False | True |
| PUMP_SC1 | False | True | False | True | False | False | False | False | True | False | True | True | False | False | False | False |
Creating a matrix for parts utilisation
We can also create a matrix, with endproducts in the index and parts as columns and the values representing some value (for example cost or quantity or something else). This is very helpful, for further analysis, like similarity searches and product clustering.
G.out_edges(['PUMP_RV1'], data=True)OutEdgeDataView([('PUMP_RV1', 'MOTOR_A1', {'quantity': 1}), ('PUMP_RV1', 'CASE_STD1', {'quantity': 1}), ('PUMP_RV1', 'VANE_ASM1', {'quantity': 1}), ('PUMP_RV1', 'OIL_SYSTEM1', {'quantity': 1})])elist = [[u, v, data['quantity']] for u,v,data in G.out_edges(['PUMP_RV1'], data=True)]
elist[['PUMP_RV1', 'MOTOR_A1', 1],
['PUMP_RV1', 'CASE_STD1', 1],
['PUMP_RV1', 'VANE_ASM1', 1],
['PUMP_RV1', 'OIL_SYSTEM1', 1]]get_all_successor_edges
def get_all_successor_edges(
G, node_id, attrs:NoneType=None, default:NoneType=None
):
Return a list of all edge pairs for node_id with the specified attributes.
get_all_predecessor_edges
def get_all_predecessor_edges(
G, node_id, attrs:NoneType=None, default:NoneType=None
):
Return a list of all predecessor edges for node_id with the specified attributes.
get_all_successor_edges(G, 'PUMP_RV1', attrs=['quantity', 'missing_attr'], default='test')[{'source': 'PUMP_RV1',
'from': 'PUMP_RV1',
'to': 'MOTOR_A1',
'quantity': 1,
'missing_attr': 'test'},
{'source': 'PUMP_RV1',
'from': 'PUMP_RV1',
'to': 'CASE_STD1',
'quantity': 1,
'missing_attr': 'test'},
{'source': 'PUMP_RV1',
'from': 'PUMP_RV1',
'to': 'VANE_ASM1',
'quantity': 1,
'missing_attr': 'test'},
{'source': 'PUMP_RV1',
'from': 'PUMP_RV1',
'to': 'OIL_SYSTEM1',
'quantity': 1,
'missing_attr': 'test'},
{'source': 'PUMP_RV1',
'from': 'VANE_ASM1',
'to': 'VANE_001',
'quantity': 6,
'missing_attr': 'test'},
{'source': 'PUMP_RV1',
'from': 'VANE_ASM1',
'to': 'BEARING_01',
'quantity': 2,
'missing_attr': 'test'}]get_all_successor_edges(G, 'BEARING_01')[]get_all_predecessor_edges(G, 'PUMP_RV1')[]get_all_predecessor_edges(G, 'BEARING_01')[{'source': 'BEARING_01', 'from': 'VANE_ASM1', 'to': 'BEARING_01'},
{'source': 'BEARING_01', 'from': 'VANE_ASM2', 'to': 'BEARING_01'},
{'source': 'BEARING_01', 'from': 'PUMP_RV1', 'to': 'VANE_ASM1'},
{'source': 'BEARING_01', 'from': 'PUMP_RV2', 'to': 'VANE_ASM2'}]dfs = [pd.DataFrame(get_all_successor_edges(G, root, attrs=['quantity'])) for root in get_all_roots(G)]
dfs[:2][ source from to quantity
0 PUMP_RV1 PUMP_RV1 MOTOR_A1 1
1 PUMP_RV1 PUMP_RV1 CASE_STD1 1
2 PUMP_RV1 PUMP_RV1 VANE_ASM1 1
3 PUMP_RV1 PUMP_RV1 OIL_SYSTEM1 1
4 PUMP_RV1 VANE_ASM1 VANE_001 6
5 PUMP_RV1 VANE_ASM1 BEARING_01 2,
source from to quantity
0 PUMP_RV2 PUMP_RV2 MOTOR_A1 1
1 PUMP_RV2 PUMP_RV2 CASE_STD1 1
2 PUMP_RV2 PUMP_RV2 VANE_ASM2 1
3 PUMP_RV2 VANE_ASM2 VANE_002 6
4 PUMP_RV2 VANE_ASM2 BEARING_01 2]final_df = pd.concat(dfs)
final_df.head()| source | from | to | quantity | |
|---|---|---|---|---|
| 0 | PUMP_RV1 | PUMP_RV1 | MOTOR_A1 | 1 |
| 1 | PUMP_RV1 | PUMP_RV1 | CASE_STD1 | 1 |
| 2 | PUMP_RV1 | PUMP_RV1 | VANE_ASM1 | 1 |
| 3 | PUMP_RV1 | PUMP_RV1 | OIL_SYSTEM1 | 1 |
| 4 | PUMP_RV1 | VANE_ASM1 | VANE_001 | 6 |
final_df.columns = ['head', 'parent', 'child', 'quantity']
final_df.head()| head | parent | child | quantity | |
|---|---|---|---|---|
| 0 | PUMP_RV1 | PUMP_RV1 | MOTOR_A1 | 1 |
| 1 | PUMP_RV1 | PUMP_RV1 | CASE_STD1 | 1 |
| 2 | PUMP_RV1 | PUMP_RV1 | VANE_ASM1 | 1 |
| 3 | PUMP_RV1 | PUMP_RV1 | OIL_SYSTEM1 | 1 |
| 4 | PUMP_RV1 | VANE_ASM1 | VANE_001 | 6 |
final_df.pivot_table(index='head', columns='child', values='quantity', aggfunc='sum')| child | BEARING_01 | BEARING_02 | CASE_CL1 | CASE_SC1 | CASE_STD1 | CLAW_001 | CLAW_ASM1 | MOTOR_A1 | MOTOR_B1 | OIL_SYSTEM1 | SCREW_001 | SCREW_ASM1 | VANE_001 | VANE_002 | VANE_ASM1 | VANE_ASM2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| head | ||||||||||||||||
| PUMP_CL1 | NaN | 4.0 | 1.0 | NaN | NaN | 2.0 | 1.0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| PUMP_RV1 | 2.0 | NaN | NaN | NaN | 1.0 | NaN | NaN | 1.0 | NaN | 1.0 | NaN | NaN | 6.0 | NaN | 1.0 | NaN |
| PUMP_RV2 | 2.0 | NaN | NaN | NaN | 1.0 | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | 6.0 | NaN | 1.0 |
| PUMP_SC1 | NaN | 4.0 | NaN | 1.0 | NaN | NaN | NaN | NaN | 1.0 | NaN | 2.0 | 1.0 | NaN | NaN | NaN | NaN |
create_matrix
def create_matrix(
G, attrs:list=['quantity'], root_nodes:NoneType=None
):
Creates a matrix with endproducts as indices and parts as columns and values as attributes
create_matrix(G)| quantity | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| child | BEARING_01 | BEARING_02 | CASE_CL1 | CASE_SC1 | CASE_STD1 | CLAW_001 | CLAW_ASM1 | MOTOR_A1 | MOTOR_B1 | OIL_SYSTEM1 | SCREW_001 | SCREW_ASM1 | VANE_001 | VANE_002 | VANE_ASM1 | VANE_ASM2 |
| head | ||||||||||||||||
| PUMP_CL1 | NaN | 4.0 | 1.0 | NaN | NaN | 2.0 | 1.0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| PUMP_RV1 | 2.0 | NaN | NaN | NaN | 1.0 | NaN | NaN | 1.0 | NaN | 1.0 | NaN | NaN | 6.0 | NaN | 1.0 | NaN |
| PUMP_RV2 | 2.0 | NaN | NaN | NaN | 1.0 | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | 6.0 | NaN | 1.0 |
| PUMP_SC1 | NaN | 4.0 | NaN | 1.0 | NaN | NaN | NaN | NaN | 1.0 | NaN | 2.0 | 1.0 | NaN | NaN | NaN | NaN |